À force de comparer la data à du pétrole, il fallait trouver le gisement ! La question du stockage et de l’accès aux données massives est devenue centrale dans une démarche globale de Business Intelligence. C’est pourquoi le concept du data lake est intéressant à considérer, pour stocker rapidement de gros volumes de données et les exploiter avec toutes sortes d’outils d’analyse et de traitement.
Voici donc les questions de base à se poser pour comprendre son intérêt dans une stratégie BI, et appréhender son fonctionnement dans l’architecture des données d’entreprise.
Auteur : Charles Parat
#1 Qu’est-ce qu’un data lake ?
Un data lake, ou lac de données, est un mode de collecte et de stockage de données massives, rendu populaire par le développement du big data depuis 2010. Il emprunte les mêmes caractéristiques : stocker rapidement et de manière permanente un gros volume de données de formats et de sources très variés. Les données y sont stockées dans leurs formats d’origine ou très peu transformées. Ce sont le plus souvent des mécanismes de data capture (plus que d’ETL/ELT) qui l’alimentent, pour garantir la réplication brute depuis des sources qualifiées. Pour en explorer et qualifier le contenu, il est bienvenu d’équiper le Data lake de fonctionnalités d’analyse, de préparation ou d’intelligence artificielle de très forte capacité et sur des spectres de formats potentiellement hétéroclites.
#2 Quelle est la différence entre un data lake et un data warehouse ?
Tous les composants d’une architecture, répondent à un besoin d’usage et/ou une contrainte technique ou fonctionnelle. Le data lake obéit à la nécessité de capter et stocker en un seul contenant (physique ou logique) des données fabriquées par d’autre systèmes internes ou externes sur un maille de finesse ou de temporalité déterminée. On sait quels systèmes amont doivent se déverser dans le data lake, mais on n’a pas forcément examiné le contenu exact de chacune de ces sources.
De son côté un data warehouse est un entrepôt centré sur des usages de business intelligence communs autour d’un ou plusieurs sujets. Il est donc en principe conçu pour ne contenir que de la donnée utile, qualifiée, organisée, et on sait à un moment donné en cartographier les usages.
Pour des raisons évidentes de simplification et de sécurité des traitements, un data warehouse repose souvent sur une couche de données, copie des sources déterminées et qu’on appelle un ODS (Operational Data Store). Cette couche est fréquemment confondue à tort avec un data lake. Son usage est transitoire, le temps d’assurer que la nouvelle mise à jour d’un data warehouse ne doive pas être re-jouée en cas d’incident de production.
Le data lake est persistent : on compte sur lui pour être le reflet fidèle, asynchrone et quelquefois temps réel de systèmes informatiques amont. De ce fait, si le data lake comporte les données qui intéressent la base sujet du data warehouse, il n’y a plus forcément besoin d’ODS, et le data warehouse est alors un client du Data lake.
Les contraintes techniques de temps de traitement, de sécurité ou de simplification des supports de stockage servant des besoins différents, ont amené très tôt les métiers IT du décisionnel à concevoir des vues métiers très proches des outils d’analyse ou de restitution, qu’on appelle des datamarts, et qui répondent à des usages très précis de données qui trouvent le plus souvent leur source dans des data warehouses. Comme un étage ultime de stockage des données métiers.
Mais aujourd’hui, les contraintes techniques ont largement reculé, et il est souvent possible de réduire le nombre de composants techniques de cette architecture en utilisant des moteurs de données à très forte capacité et en mesure d’accueillir en frontal direct tous types d’outils d’analyse, de reporting ou d’IA. Des solutions cloud de bases colonnes et/ou NOSQL, ou des logiciels de data virtualisation sont potentiellement capables de gérer aussi bien un data lake qu’un data warehouse. D’un point de vue logique, les deux niveaux de collecte et de stockage (voire trois avec les datamarts) obéissent à des besoins bien différents, mais alors potentiellement animés par un même moteur logiciel. La gouvernance du modèle selon les niveaux sera alors clé dans la maintenance et l’évolution de l’architecture.
#3 Quelles données collecter, comment classifier les données et à qui donner accès au data lake?
La première des questions porte sur le périmètre des données à déverser dans le data lake. Compte tenu du coût et du temps passé sur la création, la production et la maintenance de ce composant souvent nouveau dans l’architecture des données, il faut se poser le POUR QUOI et le POUR QUI. Mais on peut aussi rêver d’un contenu physique ou logique où l’ensemble des données de l’entreprise se retrouvent, internes comme externes et ce, quels que soient les processus digitaux qui les génèrent. C’est juste une option, et le plus souvent le data lake commence par un besoin circonscrit à un usage-clé, avant de voir son périmètre de data sources augmenter au fur et à mesure de sa popularité ou de l’apparition de nouveaux besoins.
Ces questions de périmètre vont vous servir à définir le « data management » du data lake, de ses sources et de ses clients dans l’architecture SI, et au-delà, sa politique de gestion des données, sa gouvernance.
Attention, les conformités règlementaires ne permettent plus de se contenter de collecter de la donnée sans savoir ce qu’elle est, en attendant de la découvrir. Ainsi, le RGPD (Règlement Général sur la Protection des données) par exemple, impose de créer une taxonomie qui permettra de classer les données par criticité ou sensibilité au regard du stockage et de l’utilisation des données personnelles. Vous devrez pouvoir identifier, anonymiser et supprimer les données personnelles, qui ont aussi une durée de conservation réglementée (détails sur le site de la CNIL).
La taxonomie ou classification des données est aussi ce qui vous permettra de définir des types de données, des groupes d’utilisateurs et des scénarios d’utilisation possible pour accorder des droits d’accès et guider les utilisateurs dans leur exploration des données. Les scénarios d’utilisation seront en fait les cas d’usages qui vous permettront également de mesurer le succès de votre data lake en fonction de l’utilisation qu’en feront les différentes fonctions et métiers dans l’entreprise.
#4 Quelles briques technologiques pour construire son data lake ?
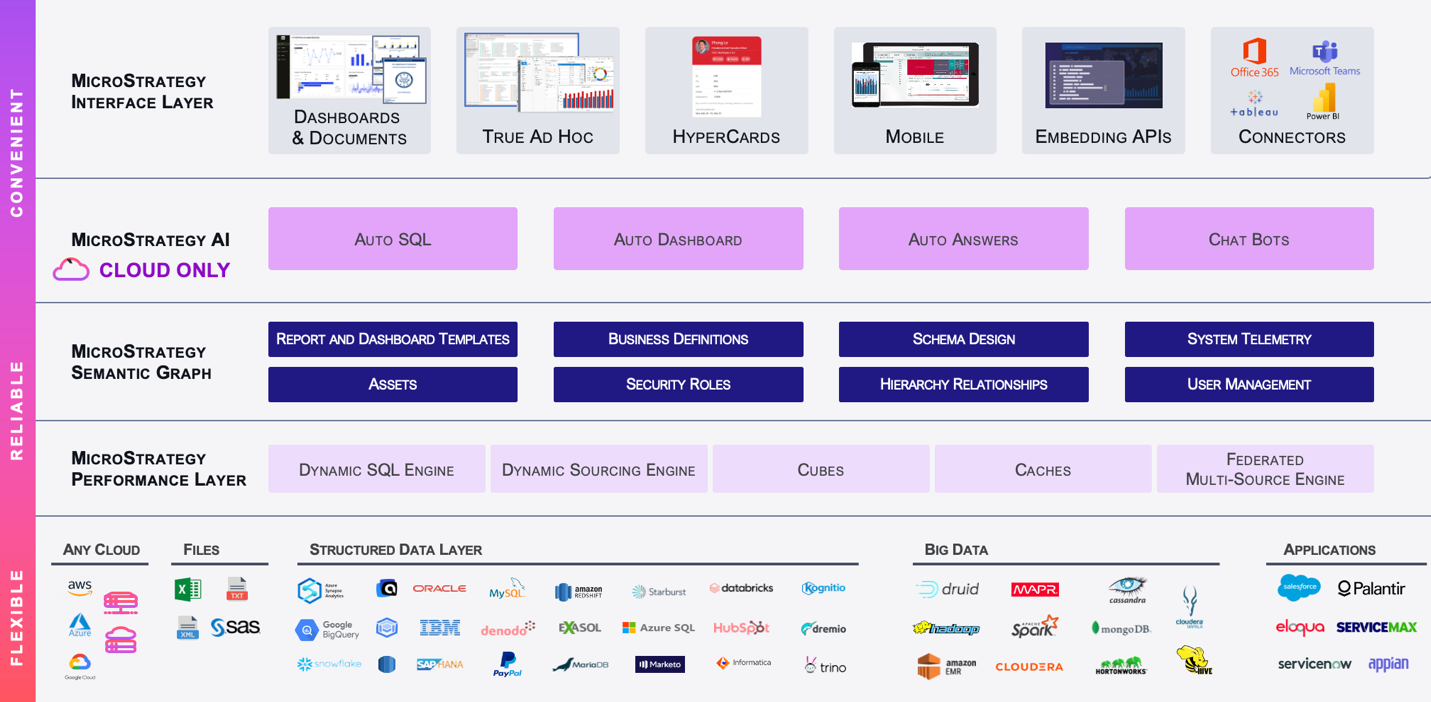
Un data lake repose sur des briques technologiques de stockage des données et on y associe logiquement le stockage des métadonnées (les informations de description et classification des données), la gestion des accès, et des fonctionnalités de production de valeur : préparation, mise en qualité, visualisation et analyse de données, et d’intelligence artificielle (notamment pour les analyses prédictives). Il existe des environnements complets intégrant toutes ces briques. On parle alors de Data Platforms.
La plupart utilisent la technologie Hadoop, un framework open source utilisé pour le stockage et le traitement des big data. La grande force d’Hadoop (et de son moteur de calcul appelé « Spark ») est sa capacité à faire du « cluster computing » (des calculs en grappes de serveurs). Le stockage des données est en effet distribué dans les nœuds d’un cluster et leur traitement y est parallélisé et donc accéléré, la performance étant un des gros challenge des projets big data. Autre intérêt d’Hadoop, mais qui fonde aussi sa complexité et sa versatilité, son écosystème qui compte plus d’une centaine de technologies pour bâtir des data lakes spécifiques aux besoins de chaque entreprise.
Vous pourrez choisir d’installer votre data lake en local ou bien dans le cloud, et même en mode « data lake as a service » (avec des solutions comme Microsoft Azure, Google Cloud Platform, Amazon S3). Les équipes Solution BI peuvent aussi vous assister sur une approche multicloud, pour assurer la performance et la redondance en cas de défaillance d’une des plateformes cloud.
#5 Quels sont les risques possibles autour d’un data lake ?
Nous avons évoqué plus haut les enjeux de gouvernance avec les questions de classification des données, de gestion des droits d’accès et de sécurisation du data lake. Car des données sensibles, confidentielles ou personnelles peuvent être collectées dans votre data lake, vous exposant à des risques de conformité et de perte ou vol de données.
Un des plus gros dangers peut en fait venir d’une collecte de données excessive et surtout non managée. On estime ainsi qu’un data lake peut contenir jusqu’à 50% de « dark data » ou « données sombres » : les données qui sont stockées par les entreprises mais qui ne sont en fait ni utilisées ni analysées. Ni même parfois vraiment répertoriées. D’après une étude de Veritas Technologies, jusqu’à 52% des données des entreprises seraient des « dark data » !
Mais ces dark data peuvent aussi être une opportunité. En effet, des informations utiles à la compréhension des comportements des clients ou à la prise de décision peuvent se cacher dans les dark data de l’entreprise et de son écosystème. On pense par exemple aux informations liées au parcours client sur un site web.
De manière générale, le plus gros risque pour le data lake est celui de son discrédit dans le cas où le système Data dans son ensemble n’est pas correctement gouverné et qu’on considère le data lake comme une solution purement technique sans valeur ajoutée pour l’amélioration des performances métiers.
L’acculturation des métiers à la richesse et à la maîtrise du système Data passe par l’explication de l’architecture logique et de la compréhension des données captées, utilisées ou non. Si le data lake reste une affaire de data engineer il faudra développer des trésors de persuasion et de démonstrations pour y intéresser les métiers et en tirer un véritable ROI.
La cartographie des données décisionnelles est une obligation aussi pour la pertinence vis-à-vis des métiers, et on n’omettra pas de faire le lien entre les cartographies techniques souvent complexes et les glossaires métiers. Rendre les métiers data intelligents est un enjeu de progrès data driven. Et ces correspondances technico-fonctionnelles permettront aussi aux acteurs IT de mieux comprendre la contribution des données à l’amélioration des processus métiers.
En conclusion
Il est important de bien définir sa politique de gestion de la donnée avant de plonger dans le data lake et d’en faire un pilier de son architecture de services BI. L’accompagnement d’un spécialiste comme Solution BI vous permettra de choisir la bonne architecture, pour un data lake à la fois performant, sécurisé et que les utilisateurs auront envie d’explorer via l’analyse de données. Un système parfaitement maitrisé permet même de donner de la perspective au métier dans la création de valeur, si la démarche Data lake intègre en parallèle une organisation data lab au sein de l’organisation. Mais c’est un autre sujet passionnant à suivre…
À lire également :
Business Intelligence : 5 raisons pour passer au full cloud, en toute sécurité
Data visualisation : 4 étapes pour bien débuter