Le contexte
Imaginez que vous êtes le nouveau DSI d’un groupe international.
Un des premiers chantiers que vous voulez entreprendre est d’harmoniser l’écosystème data.
Vous comprenez que l’approche Data Mesh doit donner une forte autonomie aux équipes, mais vous n’oubliez pas qu’un des aspects les plus importants du Data Mesh est la Gouvernance Fédérée.
Cet article traite de la mise en place d’une Gouvernance Fédérée au-dessus de Snowflake.
Un peu de vocabulaire
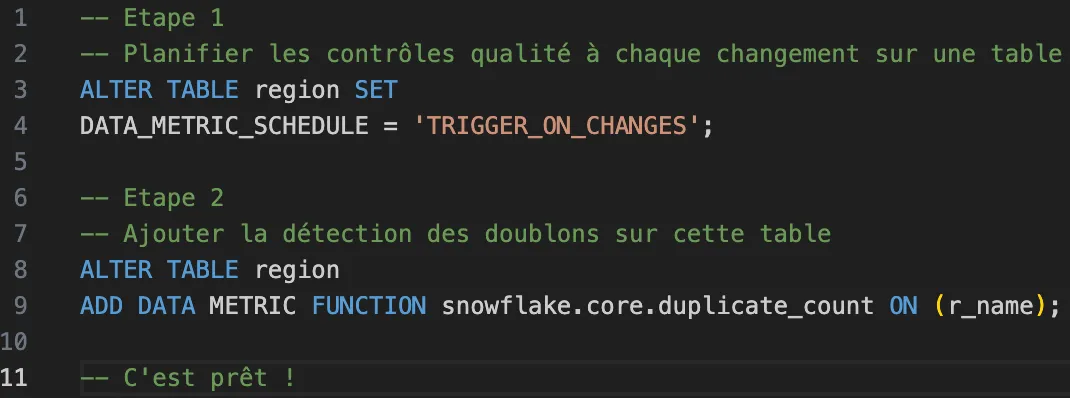
Dans Snowflake, vous avez à votre disposition plusieurs conteneurs pour “ranger” vos données.
Voici leur hiérarchie :
C’est tout pour la technique. Parlons maintenant de ce qui fait le sel des architectures data.
La gouvernance Snowflake
Pour garantir le bon usage des données et de l’outil Snowflake, vous pouvez vouloir surveiller les éléments suivants :
- La classification des données.
- L’application des tags obligatoires (par example : PRIVACY_CATEGORY et SEMANTIC_CATEGORY) pour identifier les données sensibles.
- Le respect de certaines règles de nommage.
- La mise en place de règles de masquage (masking policy).
- L’utilisation de restrictions d’accès aux données (row access policy, aggregation policy, projection policy).
- L’historique d’accès à certains objets sensibles (access history).
- Le suivi financier de l’usage des ressources.
- Les règles de sécurité réseau (network policies) ou de gestion des unités de calcul (warehouses) avec des règles spécifiques (resource monitor).
- La sécurité des accès (SSO, MFA, key/pair).
Tous les éléments de gouvernance sont réunis sous une nouvelle bannière qui s’appelle Snowflake Horizon et qui ne cesse de s’enrichir.
3 options pour gérer sa gouvernance
Comme je le disais pour attirer votre attention, nous avons 3 options pour gérer les comptes :
1️⃣ Utiliser un seul compte et séparer les départements dans des bases de données
2️⃣ Utiliser plusieurs comptes et déployer votre gouvernance depuis votre CI/CD
3️⃣ Utiliser plusieurs comptes dont un Zero Data Account qui porte la gouvernance
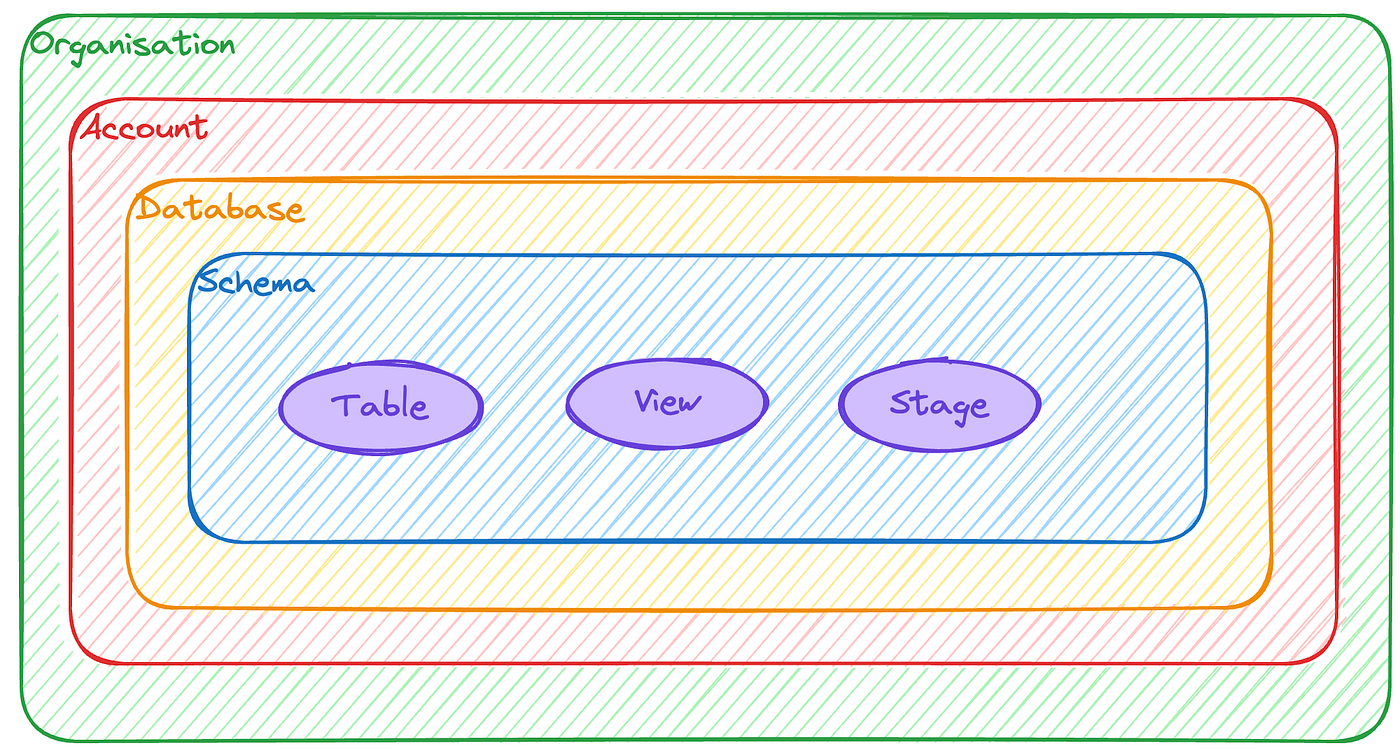
Option 1 : Compte unique
On peut, et d’ailleurs on a fait comme cela pendant des années, utiliser un compte Snowflake unique et isoler les départements dans des bases de données.
Voici un exemple dans un schéma :

Avantages :
- Les jointures sont possibles directement
- La gouvernance très simple : on accès directement à toutes les méta-données
Inconvénients :
- L’isolation des données passera uniquement par la gestion des rôles
- Les rôles vont se multiplier, on peut rapidement se retrouver avec plusieurs dizaines de rôles
Option 2 : Plusieurs comptes avec déploiement par CI/CD
On peut utiliser un compte DSI et un compte par département qui a la capacité d’opérer son propre snowflake. En effet, si ce n’est pas le cas, c’est peut être préférable de garder les objets au niveau du compte DSI et de fournir un service complet aux filiales.
Pour déployer les éléments de gouvernance (tags, masking policies, etc.) on ne va pas jouer des scripts à la main, pas de ça chez nous.
On va utiliser une CI/CD (par exemple le couple Github Actions + schemachange) pour exécuter automatiquement les scripts sur les différents comptes snowflake.
On peut utiliser aussi l’intégration de git directement dans Snowflake et coder une procédure qui gère les déploiements. J’en parlerai dans un futur article.
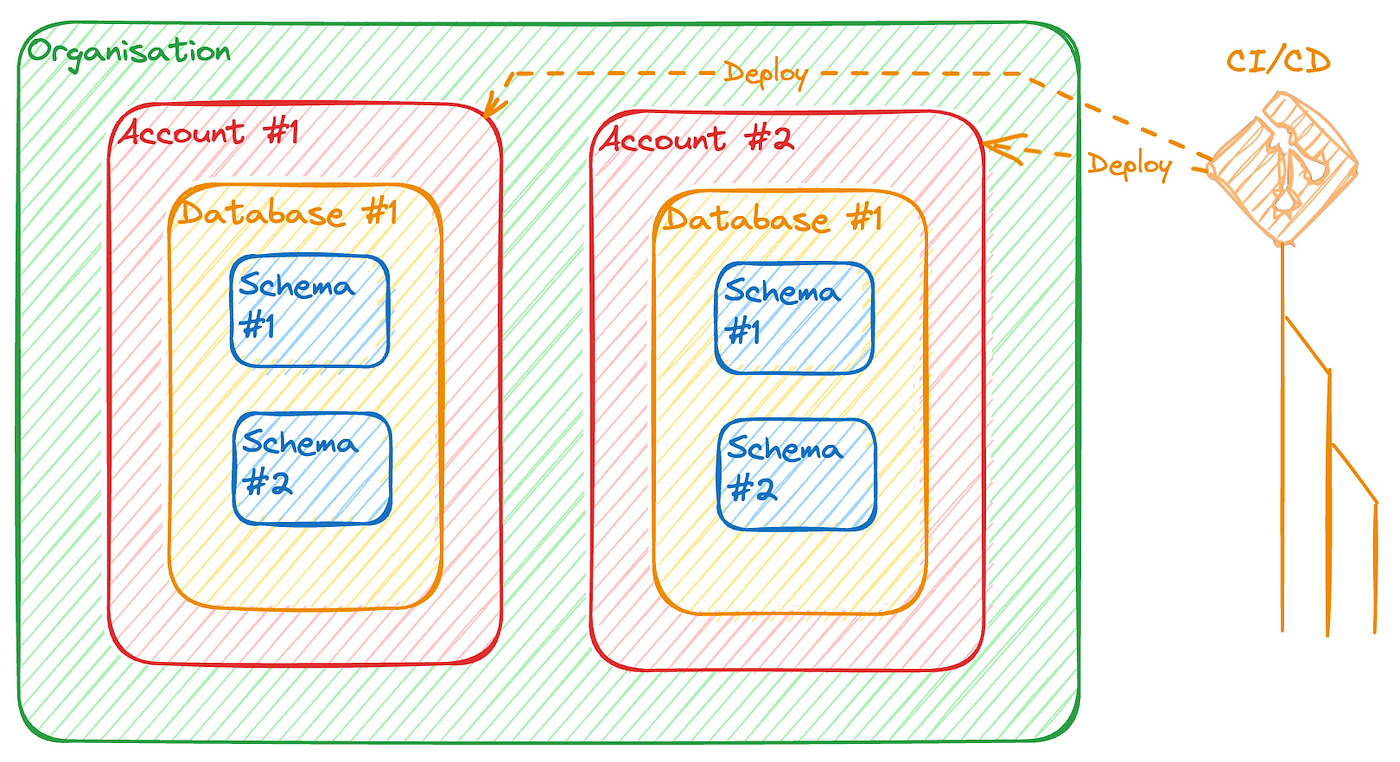
Attention : on ne pourra pas faire des jointures d’un compte à l’autre directement dans nos requêtes.
On va publier l’objet partagé (table, vue, etc) sur un Private Listing qui sera accessible à un ou plusieurs comptes.
Je vois cette contrainte comme une opportunité de gérer ses publications de data products de manière plus maîtrisée. Car quand on sait que l’on est producteur de données, on se doit de fournir à ses consommateurs une expérience de qualité (une documentation, des données de qualité, pas de modification du contrat d’interface, etc).
Avantages :
- Le découpage des responsabilités et des données est plus clair
- Moins de rôles
Inconvénients :
- On ne peut pas faire des jointures mais on doit passer par des opérations de publications
Option 3 : Plusieurs comptes dont un Zero Data Account
L’approche de Zero Data Account est nouvellement possible chez Snowflake grâce à l’arrivée des Replication Group. Mais le principe est simple et répandu dans les approches DevOps (par ex. avec AWS Control Tower).
Au lieu d’utiliser une CI/CD, on va déployer les éléments de gouvernance directement depuis snowflake à travers les groupes de réplication qui seront déployés sur les autres comptes de la même organisation.
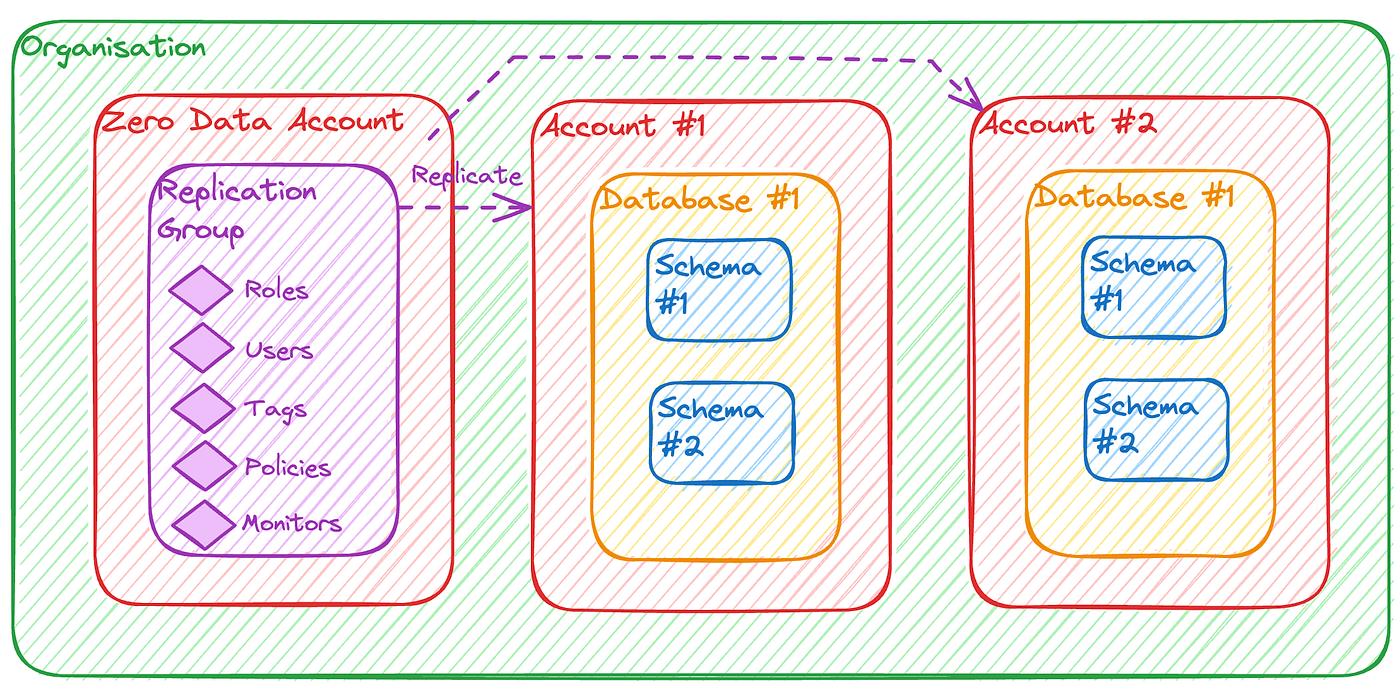
On va pouvoir centraliser toutes les informations de gouvernance citées précédemment au niveau de ce Zero Data Account qui, comme son nom l’indique, n’a pas vocation à héberger des données.
Le Zero Data Account doit être au niveau de souscription Business Critical pour pouvoir utiliser la réplication des objets de gouvernance.
Je n’ai pas trouvé dans la doc si les comptes cibles devaient être aussi en Business Critical mais il me semble que non.
Pour savoir si les comptes ont bien utilisé les éléments de gouvernance, on pourra leur demander de nous partager les tables de medata comme par exemple SNOWFLAKE.ACCOUNT_USAGE.TAG_REFERENCE.
Mais on peut aussi se parler entre humains lors des points de gouvernance fédérée. Je préfère cela.
Avantages :
- Le déploiement est géré depuis snowflake
- La supervision et l’audit sont centralisés
Inconvénients :
- Il faut un certain nombre de comptes pour justifier la création du Zero Data Account, pour seulement 2 ou 3 cela ne semble pas nécessaire.
Conclusion
Utiliser Snowflake, c’est simple.
Administrer Snowflake dans une grande entreprise en garantissant une consistance de la gouvernance au sein des divers comptes, ça demande un peu plus de réflexion.
Sans cela, où serait le plaisir ?!
Sources
Webinar : Gouvernance des données dans un data mesh — DCWT 23 — Jade Le Van, Nicolas Lerose
Masterclass: Deliver a Domain-Driven Data Mesh Architecture Successfully